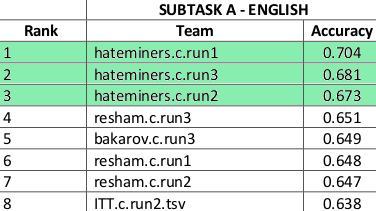
 Results
Results
Probing LLMs for hate speech detection: strengths and vulnerabilities
Abstract
Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute ‘jailbreak’ prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.