Abstract
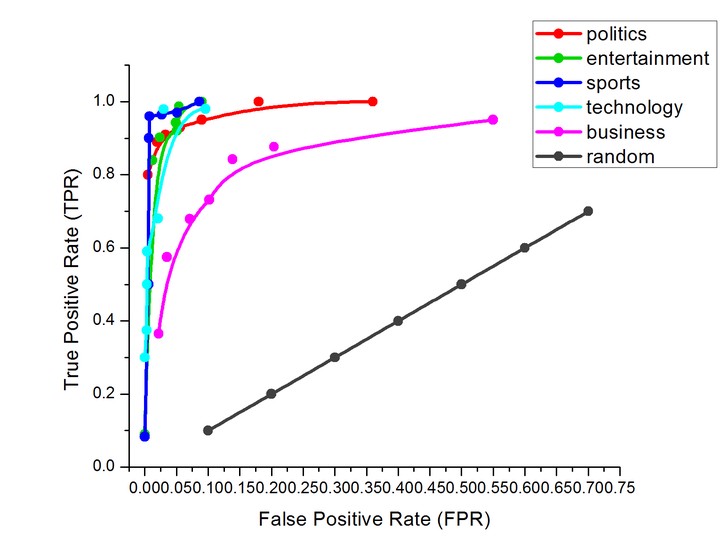
This paper proposes a document classification model using feature learning approach based on semantics of the documents. In the learning phase, basic vocabulary (BV) for each document class consisting of nouns has been created by proposing a novel approach. The classification phase searches unique words in the BVs and if found, the corresponding sentence becomes a basic sentence (BS). A tree with unique words of the BS is inserted in the respective forest. Associated words of the children are used to continue the tree formation process until no new node is generated in the tree. Finally, we assign the test document to a class which has a clearly dominant percentage of sentences in the respective forest. The proposed algorithm is compared with various feature-based classification models and satisfactory performance has been observed.