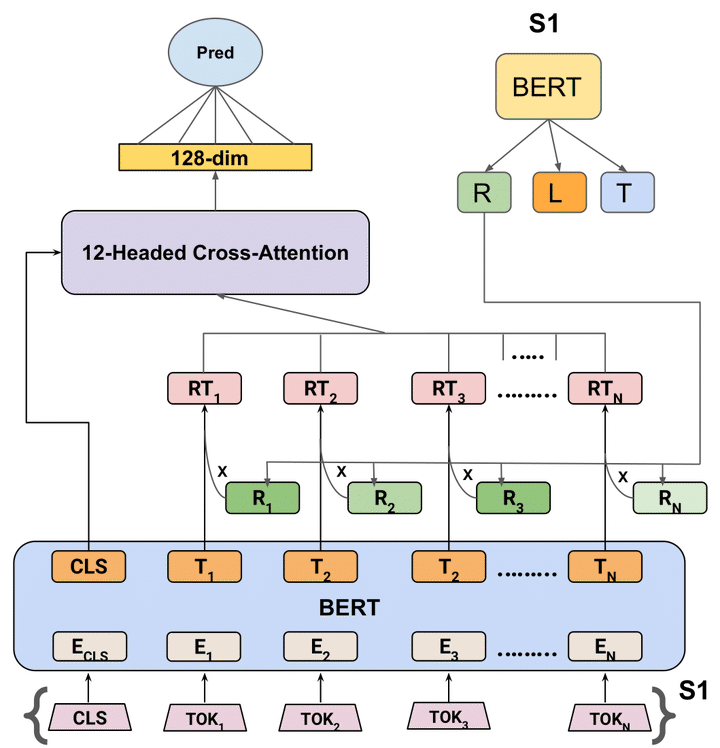
Abstract
Abusive language is a concerning problem in online social media. Past research on detecting abusive language covers different platforms, languages, demographies, etc. However, models trained using these datasets do not perform well in cross-domain evaluation settings. To overcome this, a common strategy is to use a few samples from the target domain to train models to get better performance in that domain (cross-domain few-shot training). However, this might cause the models to overfit the artefacts of those samples. A compelling solution could be to guide the models toward rationales, i.e., spans of text that justify the text’s label. This method has been found to improve model performance in the in-domain setting across various NLP tasks. In this paper, we propose RGFS (Rationale-Guided Few-Shot Classification) for abusive language detection. We first build a multitask learning setup to jointly learn rationales, targets, and labels, and find a significant improvement of 6% macro F1 on the rationale detection task over training solely rationale classifiers. We introduce two rationale-integrated BERT-based architectures (the RGFS models) and evaluate our systems over five different abusive language datasets, finding that in the few-shot classification setting, RGFS-based models outperform baseline models by about 7% in macro F1 scores and perform competitively to models finetuned on other source domains. Furthermore, RGFS-based models outperform LIME/SHAP-based approaches in terms of plausibility and are close in performance in terms of faithfulness
Link to the supplementary file
Main contributions
Coming soon
Limitations
Coming soon
Future Directions
Coming soon