HateProof: Are Hateful Meme Detection Systems really Robust?
Abstract
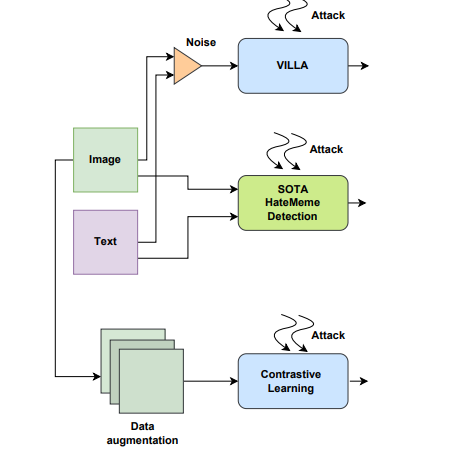
Exploiting social media to spread hate has tremendously increased over the years. Lately, multi-modal hateful content such as memes has drawn relatively more traction than uni-modal content. Moreover, the availability of implicit content payloads makes them fairly challenging to be detected by existing hateful meme detection systems. In this paper, we present a use case study to analyze such systems’ vulnerabilities against external adversarial attacks. We fnd that even very simple perturbations in uni-modal and multimodal settings performed by humans with little knowledge about the model can make the existing detection models highly vulnerable. Empirically, we fnd a noticeable performance drop of as high as 10% in the macro-F1 score for certain attacks. As a remedy, we attempt to boost the model’s robustness using contrastive learning as well as an adversarial training-based method - VILLA. Using an ensemble of the above two approaches, in two of our high resolution datasets, we are able to (re)gain back the performance to a large extent for certain attacks. We believe that ours is a frst step toward addressing this crucial problem in an adversarial setting and would inspire more such investigations in the future.